Quantencomputer sind eine aufregende Technologie, die das Potenzial hat, unsere herkömmlichen Computer in Bezug auf Rechenleistung und Problemlösungsfähigkeiten zu revolutionieren. Doch wie genau funktionieren diese bahnbrechenden Maschinen?
Um das Konzept von Quantencomputern zu verstehen, müssen wir zunächst einige Grundlagen der Quantenmechanik verstehen. In der Quantenphysik existieren Partikel auf mikroskopischer Ebene nicht nur in einem bestimmten Zustand, sondern können sich in sogenannten Superpositionen befinden. Dies bedeutet, dass sie gleichzeitig verschiedene Zustände einnehmen können.
Die grundlegende Einheit eines Quantencomputers ist das Quantenbit, kurz Qubit. Im Gegensatz zu herkömmlichen Bits, die entweder den Wert 0 oder 1 haben können, können Qubits aufgrund ihrer quantenmechanischen Eigenschaften in einer Superposition aus 0 und 1 gleichzeitig existieren. Dadurch können Qubits mehr Informationen gleichzeitig verarbeiten.
Quantencomputer nutzen die Eigenschaften der Quantenmechanik, um komplexe Berechnungen durchzuführen. Durch Quantenüberlagerung können Qubits gleichzeitig in verschiedenen Zuständen sein und somit parallele Berechnungen durchführen. Zudem können Qubits verschränkt werden, was bedeutet, dass der Zustand eines Qubits von einem anderen Qubit abhängig ist. Dies ermöglicht eine starke Verknüpfung und parallele Verarbeitung von Informationen.
Quantencomputer verwenden spezielle Quantenalgorithmen, um komplexe Probleme zu lösen. Einer der bekanntesten Quantenalgorithmen ist der Shor-Algorithmus, der zur Faktorisierung großer Zahlen verwendet wird. Durch die gleichzeitige Verarbeitung von Informationen und die Ausnutzung der Verschränkung können Quantencomputer komplexe Berechnungen deutlich schneller durchführen als herkömmliche Computer.
Beispiel des Shor Algorithmus
Der Shor-Algorithmus ist ein bedeutender Quantenalgorithmus, der verwendet wird, um große Zahlen zu faktorisieren. Angenommen, wir möchten die Zahl 21 faktorisieren, also die beiden Primfaktoren finden, aus denen sie besteht.
1. Vorbereitung
Wir wählen eine zufällige Zahl a (größer als 1 und kleiner als 21) als Ausgangspunkt. Nehmen wir der Einfachheit halber a = 2. Nun überprüfen wir, ob a und 21 teilerfremd sind, also keinen gemeinsamen Teiler haben. Wenn sie einen gemeinsamen Teiler hätten, könnten wir bereits den Primfaktor finden und wären fertig. In unserem Fall sind 2 und 21 teilerfremd.
2. Quantenüberlagerung
Wir erstellen ein Qubit-Register, das aus n Qubits besteht, wobei n die Anzahl der Stellen in der Binärdarstellung der Zahl 21 ist. In unserem Fall sind es 5 Qubits, da die Binärdarstellung von 21 „10101“ ist. Diese Qubits werden in den Superpositionszustand gebracht, in dem sie gleichzeitig alle möglichen Zustände repräsentieren. Dies ermöglicht es uns, parallele Berechnungen durchzuführen.
3. Quantenfunktion anwenden
Wir wenden eine Quantenfunktion auf das Qubit-Register an, die den Zustand des Registers gemäß der Funktion f(x) = a^x mod 21 ändert. Dabei steht x für die Binärdarstellung der Zahlen 0 bis 2^n-1 (also von 0 bis 31 in unserem Fall). Diese Funktion berechnet a^x und nimmt den Rest bei der Division durch 21.
4. Quanten-Fouriertransformation
Wir wenden eine Quanten-Fouriertransformation auf das Qubit-Register an, um die Frequenzen der Zustände zu analysieren. Durch die Fouriertransformation können wir die Periodenlänge der Funktion f(x) erkennen. Die Periodenlänge gibt uns wichtige Informationen über die Faktorisierung der Zahl 21.
5. Auswertung der Messergebnisse
Wir messen das Qubit-Register und erhalten eine bestimmte Zustandsfolge. Anhand dieser Zustandsfolge können wir die Periodenlänge bestimmen. Die Periodenlänge gibt uns Hinweise auf die Primfaktoren von 21.
In unserem Beispiel könnte die Messung ergeben, dass die Periodenlänge 6 ist. Basierend auf diesem Ergebnis können wir die Primfaktoren von 21 bestimmen. Da die Periodenlänge gerade ist, können wir eine einfache mathematische Berechnung durchführen, um die Faktoren zu finden.
Um die Primfaktoren von 21 basierend auf einer Periodenlänge von 6 zu berechnen, verwenden wir eine einfache mathematische Beziehung. Wenn die Periodenlänge (in diesem Fall 6) gerade ist, nehmen wir 2 hoch (Periodenlänge/2) und addieren 1. Das Ergebnis ist ein möglicher Kandidat für einen Primfaktor von 21.
In diesem Fall erhalten wir 2^(6/2) + 1 = 2^3 + 1 = 8 + 1 = 9.
Jetzt prüfen wir, ob 9 ein Teiler von 21 ist. Da 9 nicht gleich 21 ist, müssen wir weiter nach einem anderen Kandidaten suchen. Wir versuchen den nächsten möglichen Kandidaten, indem wir 2^(6/2) – 1 berechnen.
Das ergibt 2^3 – 1 = 8 – 1 = 7.
Da 7 ein Primfaktor von 21 ist, haben wir nun beide Primfaktoren gefunden. Die Faktoren von 21 sind 7 und (21 / 7) = 3.
Daher sind die Primfaktoren von 21: 7 und 3.
Insgesamt ist der Shor-Algorithmus ein komplexer Algorithmus, der auf den Prinzipien der Quantenmechanik basiert. Er nutzt die Eigenschaften von Quantencomputern, um Faktorisierungsprobleme deutlich schneller zu lösen als herkömmliche Computer.
Trotz des enormen Potenzials stehen Quantencomputer vor einigen Herausforderungen. Eine davon ist die Störungsanfälligkeit gegenüber Umgebungseinflüssen, die als Quantenrauschen bezeichnet wird. Forscher arbeiten intensiv daran, Fehlerkorrekturverfahren zu entwickeln, um diese Probleme zu lösen und Quantencomputer zuverlässiger zu machen.
Die Zukunft der Quantencomputer ist vielversprechend. Die Fortschritte in der Forschung und Entwicklung könnten zu bedeutenden Durchbrüchen in der Kryptographie, der Optimierung komplexer Systeme, der Medikamentenentwicklung und vielen anderen Bereichen führen. Unternehmen, Forschungseinrichtungen und Regierungen investieren intensiv in die Weiterentwicklung dieser Technologie, um ihr volles Potenzial zu erschließen.
Fazit
Quantencomputer sind faszinierende Maschinen, die auf den Prinzipien der Quantenmechanik basieren. Durch die Nutzung von Quantenüberlagerung können Rechenvorgänge weiter beschleunigt werden. Schnittstellen fortschrittlicher Quantencomputer mit verschränkten Qubits werden ohne Zeitverzögerung die Daten übertragen. Die zu einem effektiv arbeitenden, verteilten Quantencomputer dazugehörende Quantenkommunikation ist in China am weitesten fortgeschritten. Die Eliten des Westens investieren hauptsächlich in Krieg, Raub, Massenmord, Unterdrückung mit Abschaffung der Menschenrechte.
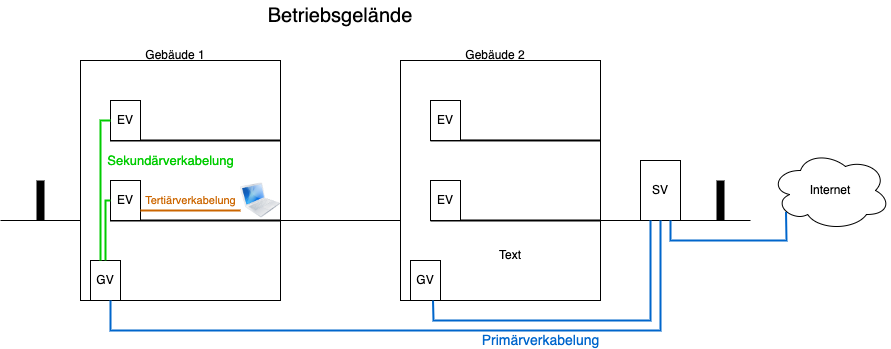 Verkabelung von Netzen
Verkabelung von Netzen

 Eingang zum Winterpalast, P. Manushin
Eingang zum Winterpalast, P. Manushin