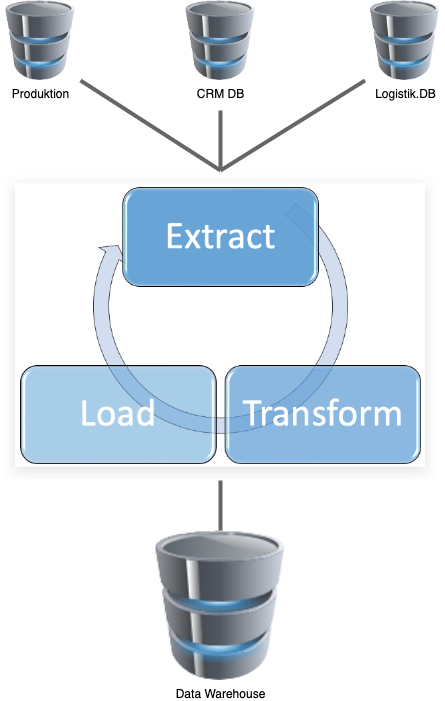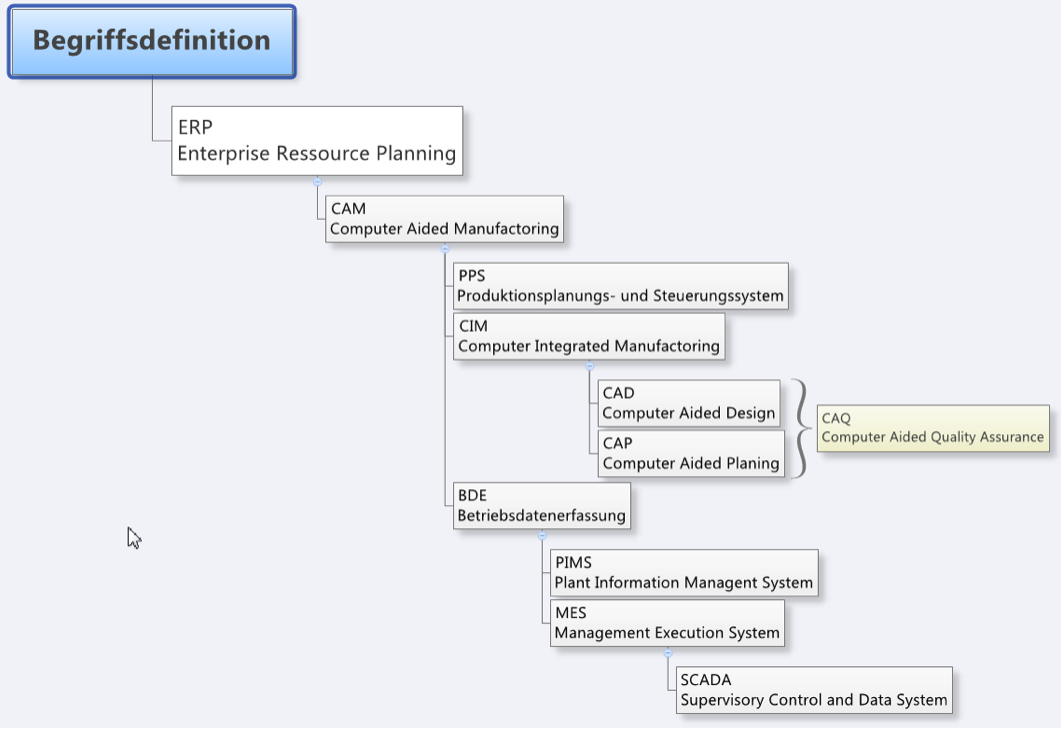

In der Welt der Datenbanktechnologien sind zwei zentrale Konzepte weit verbreitet: das ACID-Modell, das typischerweise mit relationalen (SQL) Datenbanken assoziiert wird. Das BASE-Modell wird oft mit NoSQL-Datenbanken in Verbindung gebracht. Diese Modelle definieren die grundlegenden Eigenschaften, die von den jeweiligen Datenbanksystemen erwartet werden.
ACID-Modell
ACID steht für Atomicity, Consistency, Isolation und Durability. Dieses Modell wird in relationalen Datenbankmanagementsystemen (RDBMS) eingesetzt, um die Zuverlässigkeit und Genauigkeit von Transaktionen zu gewährleisten.
- Atomicity (Atomarität): Jede Transaktion wird als eine einzelne Einheit betrachtet, die entweder vollständig erfolgreich ist oder gar nicht ausgeführt wird.
- Consistency (Konsistenz): Transaktionen führen eine Datenbank von einem konsistenten Zustand in einen anderen über, ohne die Datenintegrität zu verletzen.
- Isolation (Isolierung): Gleichzeitig ausgeführte Transaktionen beeinflussen sich nicht gegenseitig.
- Durability (Dauerhaftigkeit): Sobald eine Transaktion abgeschlossen ist, bleiben die Änderungen dauerhaft erhalten, auch im Falle eines Systemausfalls.
BASE-Modell
BASE steht für Basically Available, Soft State und Eventually Consistent. Dieses Modell wird in NoSQL-Datenbanksystemen verwendet, um Flexibilität, Skalierbarkeit und Verfügbarkeit in verteilten Systemen zu gewährleisten.
- Basically Available (Grundsätzlich verfügbar): Das System garantiert die Verfügbarkeit von Daten, auch wenn einige Teile des Systems ausgefallen sind.
- Soft State (Weicher Zustand): Der Zustand des Systems kann sich mit der Zeit ändern, auch ohne Benutzereingriffe.
- Eventually Consistent (Schließlich konsistent): Das System stellt sicher, dass, wenn keine neuen Updates mehr erfolgen, alle Replikationen der Datenbank nach einiger Zeit konsistent sind.
Vergleichstabelle
| Eigenschaft | ACID-Modell | BASE-Modell |
|---|---|---|
| Datenintegrität | Hoch | Variabel |
| Flexibilität | Gering | Hoch |
| Skalierbarkeit | Vertikal | Horizontal |
| Konsistenz | Strenge Konsistenz | Eventuelle Konsistenz |
| Transaktionsmanagement | Strikt und zuverlässig | Locker und anpassungsfähig |
| Einsatzgebiet | Traditionelle Unternehmensanwendungen | Verteilte, skalierende Anwendungen |
Fazit
Das ACID-Modell bietet hohe Datenintegrität und Zuverlässigkeit, was es ideal für Anwendungen macht, die strenge Konsistenz und Transaktionssicherheit erfordern, wie z.B. Bankensysteme. Allerdings kann es aufgrund seiner strengen Regeln zu Einschränkungen in Bezug auf Flexibilität und Skalierbarkeit kommen.
Im Gegensatz dazu bietet das BASE-Modell eine hohe Flexibilität und Skalierbarkeit, was es ideal für verteilte Systeme und Anwendungen mit großem Datenvolumen und hohen Benutzerzahlen macht, wie soziale Netzwerke oder Echtzeit-Analysen. Die eventuelle Konsistenz kann jedoch zu Herausforderungen in Anwendungen führen, die eine sofortige Datenkonsistenz erfordern.
Letztendlich hängt die Wahl zwischen ACID- und BASE-Modellen von den spezifischen Anforderungen und dem Kontext der jeweiligen Anwendung ab. Beide Modelle haben ihre Berechtigung und bieten unterschiedliche Vorteile, die je nach Einsatzgebiet entscheidend sein können.