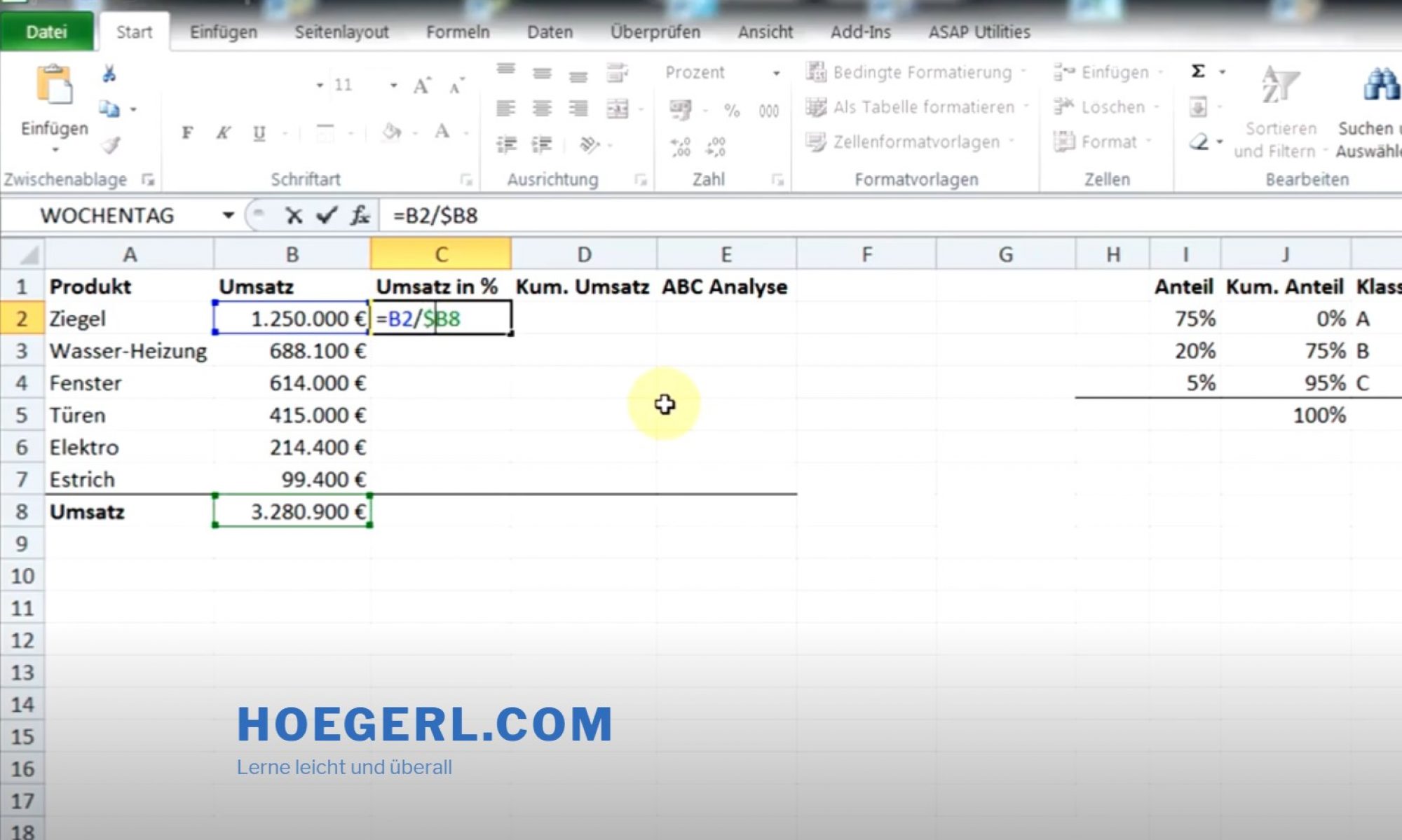

Der ETL-Prozess ist eine Abkürzung für Extraktion, Transformation und Laden. Es ist ein wesentlicher Aspekt der Datenverwaltung und insbesondere der Verarbeitung von Daten bei Big Data.
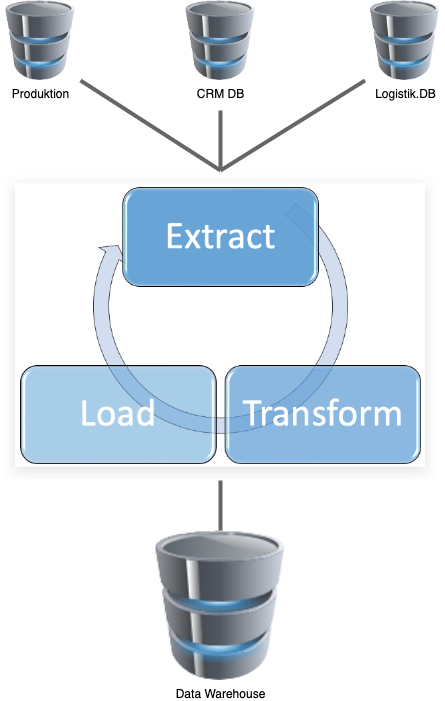
Er beginnt mit der Extraktion von Daten aus verschiedenen Quellen, die strukturiert, halbstrukturiert oder unstrukturiert sein können.
Nach der Extraktion werden die Daten transformiert, das heißt, sie werden gereinigt, bereinigt, validiert und in ein Format überführt, das von der Ziel-Datenbank gelesen werden kann. Dieser Schritt kann auch die Anreicherung von Daten mit zusätzlichen Informationen und die Durchführung komplexer Berechnungen beinhalten.
Schließlich werden die transformierten Daten in eine Zieldatenbank oder ein Data Warehouse geladen, wo sie für die Anwender im Intranet zu Analyse- und Auswertungszwecken leicht zugänglich sind.