Das Internet entstand aus dem ARPAnet, das ein Produkt des kalten Krieges zwischen der Sowjetunion und den USA war. Es wurde in den 1960er Jahren von der Advanced Research Projects Agency, einer Abteilung des US-Verteidigungsministeriums, geschaffen. Es wurde ein dezentrales Netzwerk zur Übertragung von Daten mit Datenpaketen geschaffen.
1969 begannen vier Elite Universitäten – UCLA, Stanford, UC Santa Barbara und das University of Utah Research Institute das Arpanet aufzubauen – Sie wurden als die ersten Knotenpunkte des neuen Netzwerks. Die Verbindung zwischen diesen Knotenpunkten wurde mit speziell entwickelten Schnittstellen und Protokollen hergestellt.
Im Jahr 1990 wurde das ARPAnet außer Betrieb genommen, als das Internetprotokoll IPv4 eingeführt wurde und das Netzwerk in das öffentliche Internet integriert wurde.
Da die Anzahl der im Internet genutzten Geräte im Laufe der Jahre stark anstieg, erkannten die Experten, dass der Adressraum mit 32 Bit zu stark begrenzt ist. Jede Adresse im öffentlichen Internet darf nur einmal genutzt werden. Um die vielen Unternehmensnetze zu ermöglichen, wurde die Technologie NAT (Network Address Translation) entwickelt und für die Netzwerk Klassen A bis C private Adressenpools definiert. Später wurde CIDR (Classless Inter-Domain Routing) eingeführt.
Welche privaten Adressenbereiche gibt es?
IPv4 reserviert bestimmte Adressbereiche für den privaten Gebrauch. Hier sind die drei private Adressbereiche von IPv4 mit Beispielen.
1. Private Adressbereich gemäß RFC 1918
-
-
- 10.0.0.0 bis 10.255.255.255 mit 224-2 Adressen pro Netz für Unternehmen mit großen Adressenbedarf
Beispiel:
Netzadresse 10.0.0.0
IP Adresse 10.0.1.4
Broadcast Adresse 10.255.255.255
Subnetzmaske 255.0.0.0 - 172.16.0.0 bis 172.31.255.255 mit 216-2 Adressen pro Netz für Unternehmen mit mittleren Adressenbedarf
Beispiel:
Netzadresse 172.16.0.0
IP Adresse 172.16.0.23
Broadcast Adresse 172.16.255.255
Subnetzmaske 255.255.0.0 - 192.168.0.0 bis 192.168.255.255 mit 28-2 pro Netz Adressen für Unternehmen mit geringen Adressenbedarf
Beispiel:
Netzadresse 192.168.3.0
IP Adresse 192.168.3.120
Broadcast Adresse 192.168.3.255
Subnetzmaske 255.255.255.0
- 10.0.0.0 bis 10.255.255.255 mit 224-2 Adressen pro Netz für Unternehmen mit großen Adressenbedarf
-
2. Link-Local Adressbereich gemäß RFC 3927
169.254.0.0 bis 169.254.255.255 für die Übertragung von einer Adresse zu gleichzeitig mehreren Adressen
Aufbau der Netzwerk Adressierung
Angenommen, wir haben ein Netzwerk mit der IP-Adresse 192.168.3.21 und einer Subnetzmaske von 255.255.255.0.
In diesem Fall ist die IP-Adresse 192.168.3.0 die Netzadresse, also die Adresse des vorliegenden Netzwerks.
IP-Adressen werden verwendet, um einzelne Geräte in einem Netzwerk zu identifizieren. Jedes Gerät in einem Netzwerk hat eine eindeutige IP-Adresse, wie zum Beispiel 192.168.3.1 oder 192.168.3.21.
Die Subnetzmaske gibt an, welcher Teil der IP-Adresse die Netzwerkadresse ist und welcher Teil für die Identifizierung der einzelnen Geräte im vorliegenden Netz verwendet wird. In diesem Fall ist die Subnetzmaske 255.255.255.0, was bedeutet, dass die ersten drei Zahlenblöcke (192.168.3) die Netzwerkadresse sind und der letzte Zahlenblock (0) für die Identifizierung der Geräte im Host verwendet wird.
Die Broadcast-Adresse ist die höchste Adresse in einem Netzwerk und wird verwendet, um Daten gleichzeitig an alle Geräte im Netzwerk zu senden. In unserem Beispiel wäre die Broadcast-Adresse 192.168.3.255. Wenn also ein Gerät eine Nachricht an alle anderen Geräte im Netzwerk senden möchte und die genaue IP-Adresse nicht kennt, würde es diese Adresse als Zieladresse verwenden.
Einsatzbereich der privaten IP-Adressen
Diese Adressbereiche sind für den privaten Gebrauch in lokalen Netzwerken vorgesehen. Sie können durch NAT beliebig oft in Netzen genutzt werden und werden nicht im Internet geroutet. Sie ermöglichen es vielen Organisationen jeweils eigene IP-Adressen in ihren Netzwerken zu verwenden, ohne mit öffentlichen Adressen zu kollidieren.

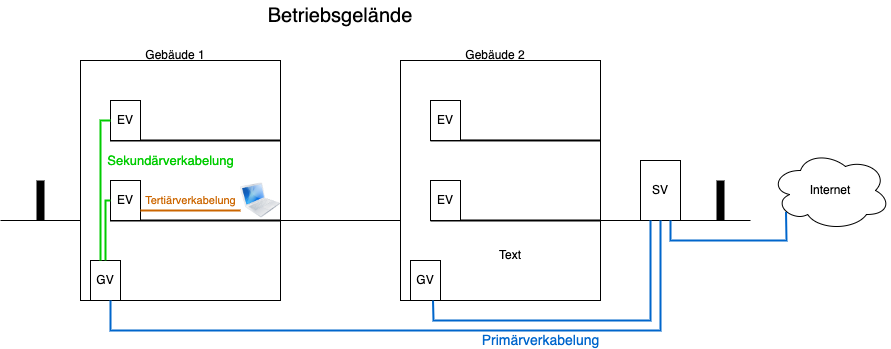 Verkabelung von Netzen
Verkabelung von Netzen



 Eingang zum Winterpalast, P. Manushin
Eingang zum Winterpalast, P. Manushin