Der Blackbox-Test und der Whitebox-Test dienen dazu, die Qualität und Zuverlässigkeit von Software- und Systemlösungen sicherzustellen. Die Tests decken verschiedene Aspekte wie Funktionalität, Benutzerfreundlichkeit, Zuverlässigkeit und Sicherheit ab. Sie werden von Anwendungsentwicklern, Systemintegratoren und weiteren Berufen in der IT Sparte eingesetzt.
Der Blackbox Test
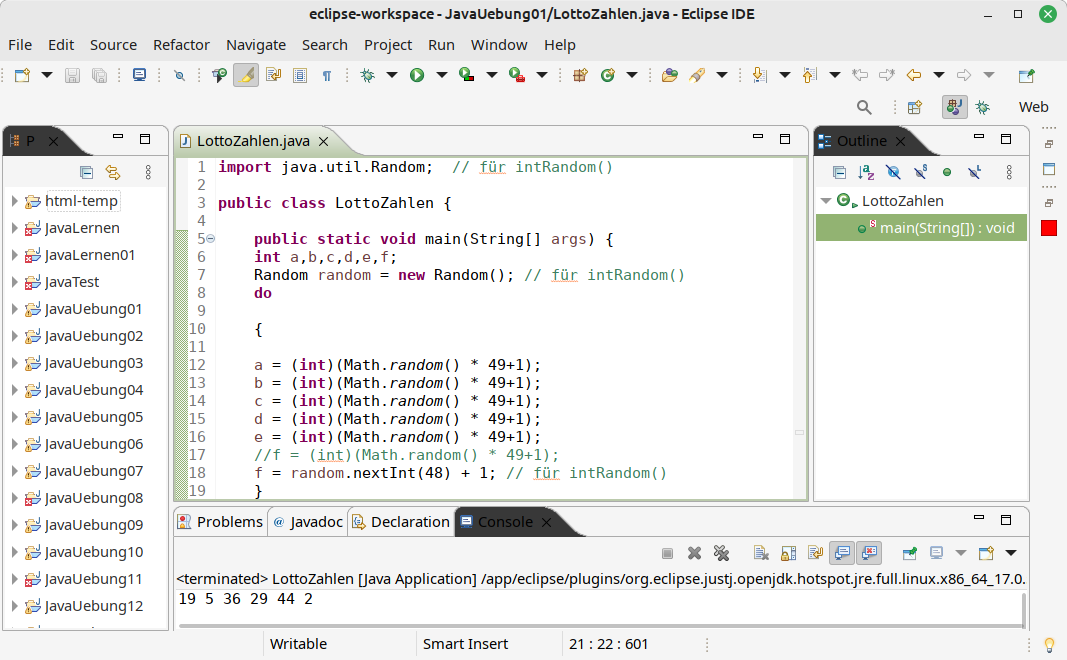
Der Blackbox-Test wird auch manchmal als Black-Box-Test beschrieben und ist ein Testverfahren, bei dem die interne Struktur oder das Design des zu testenden Systems nicht bekannt ist oder nicht berücksichtigt wird. Der Tester betrachtet das System als eine „Blackbox“, bei der er nur die Eingaben (Input) und die Ausgaben (Output) kennt. Der Fokus liegt auf der Überprüfung der funktionalen Anforderungen des Systems, wie z. B. ob es die erwarteten Ergebnisse liefert und ob es korrekt mit verschiedenen Eingabeparametern umgeht. Der Tester kann verschiedene Techniken wie Äquivalenzklassenbildung, Grenzwertanalyse, Zustandsübergangstests und zufällige Tests verwenden, um die Wirksamkeit des Systems zu überprüfen. Der Blackbox-Test ermöglicht es, das System aus Sicht des Endbenutzers zu bewerten und kann unabhängig von der internen Implementierung des Systems durchgeführt werden.
Vorteile des Blackbox-Tests
- Der Blackbox-Test stellt sicher, dass das System den Anforderungen und Erwartungen der Benutzer entspricht.
- Der Blackbox-Test kann unabhängig von der internen Implementierung durchgeführt werden.
- Durch den Blackbox-Test können Muster von Fehlern und unerwartetem Verhalten erkannt werden.
Nachteile des Blackbox-Tests
- Der Blackbox-Test kann bestimmte interne Codepfade oder -bereiche nicht ausreichend testen.
- Die Ursache von Fehlern kann aufgrund fehlenden Zugangs zur internen Implementierung schwierig zu identifizieren sein.
- Der Blackbox-Test bezieht sich nicht auf die interne Effizienz oder Optimierung des Codes.
Der Whitebox Test
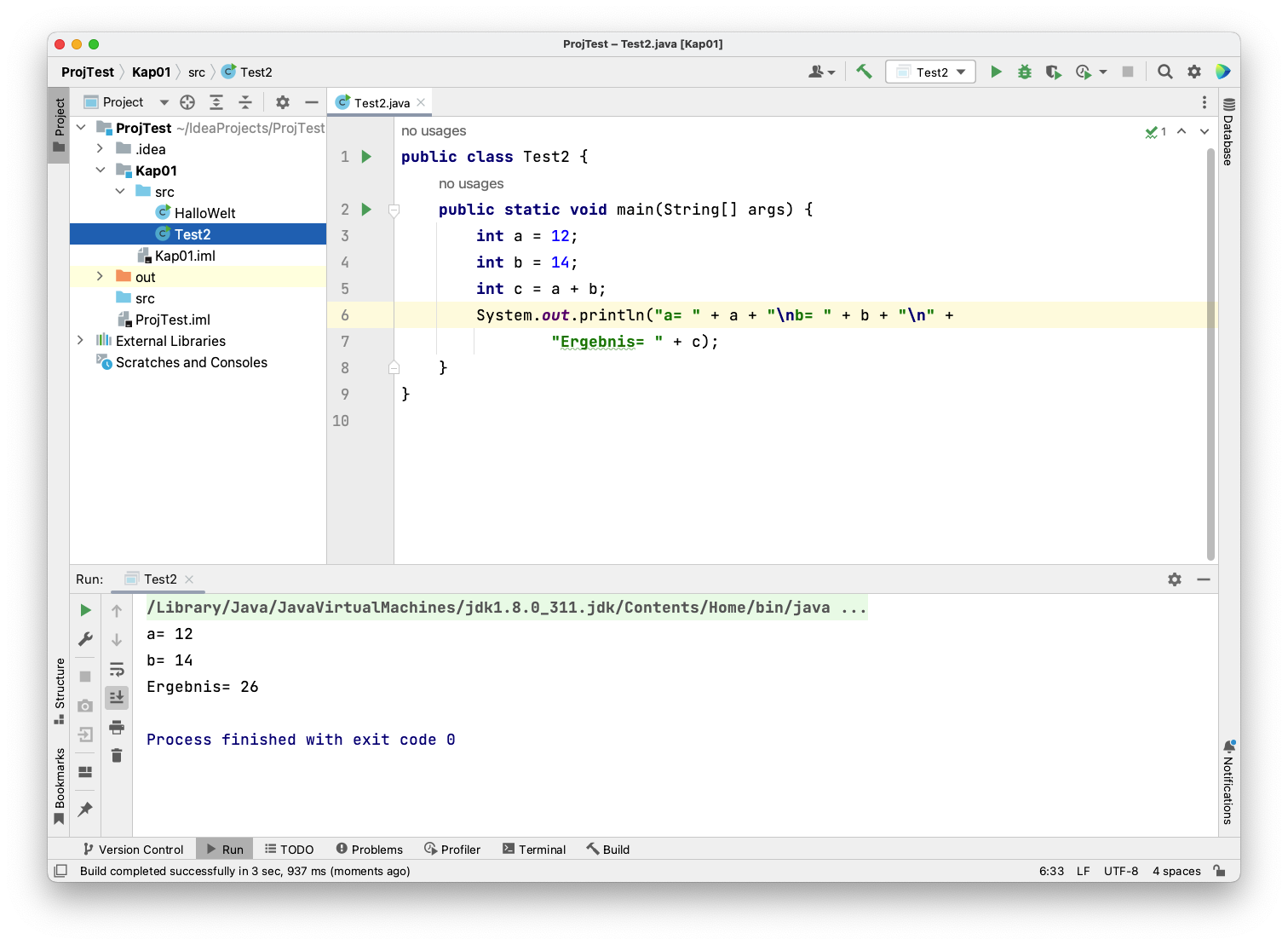
Der Whitebox-Test wird manchmal als White-Box-Test beschrieben und ist ein Testverfahren, bei dem der Tester Einblick in die interne Struktur, sowie in das Design des zu testenden Systems hat. Der Tester analysiert den Quellcode, die Algorithmen, die Datenstrukturen und andere technische Aspekte des Systems, um Tests zu erstellen, die auf diesen Informationen basieren. Der Whitebox-Test konzentriert sich sowohl auf die Überprüfung der funktionalen Anforderungen als auch auf die strukturelle Abdeckung des Codes. Es werden Techniken wie Pfadabdeckung, Anweisungsabdeckung, Zweigabdeckung und Bedingungsabdeckung verwendet, um sicherzustellen, dass alle möglichen Pfade und Szenarien im Code getestet werden. Der Whitebox-Test wird oft von Entwicklern durchgeführt, um sicherzustellen, dass der Code richtig implementiert ist und potenzielle Fehler und Schwachstellen identifiziert werden.
Vorteile des Whitebox-Tests
- Der Whitebox-Test ermöglicht eine detaillierte Überprüfung des Codes und identifiziert potenzielle Fehler auf algorithmischer oder struktureller Ebene.
- Durch den direkten Zugriff auf den Quellcode kann der Whitebox-Test eine umfassende Abdeckung der Code-Pfade und Szenarien erreichen.
- Der Whitebox-Test ermöglicht es, ineffiziente Codebereiche zu erkennen und zu optimieren, um die Gesamtleistung des Systems zu verbessern.
Nachteile des Whitebox-Tests
- Der Whitebox-Test erfordert Kenntnisse über die interne Implementierung, was zu Einschränkungen führen kann, wenn der Quellcode nicht verfügbar oder komplex ist.
- Der Whitebox-Test fokussiert sich stark auf die interne Logik und kann die Perspektive eines Endbenutzers oder externe Schnittstellen möglicherweise nicht vollständig berücksichtigen.
- Der Whitebox-Test erfordert tiefgreifende Kenntnisse der internen Struktur und erfordert mehr Zeit und Ressourcen im Vergleich zum Blackbox-Test.
Fazit
Der Blackbox-Test ermöglicht eine unabhängige Bewertung der funktionalen Anforderungen aus Benutzersicht, während der Whitebox-Test eine detaillierte Überprüfung der internen Implementierung und eine umfassendere Testabdeckung bietet. Beide Testarten sind wichtige Bestandteile der Qualitätssicherung.